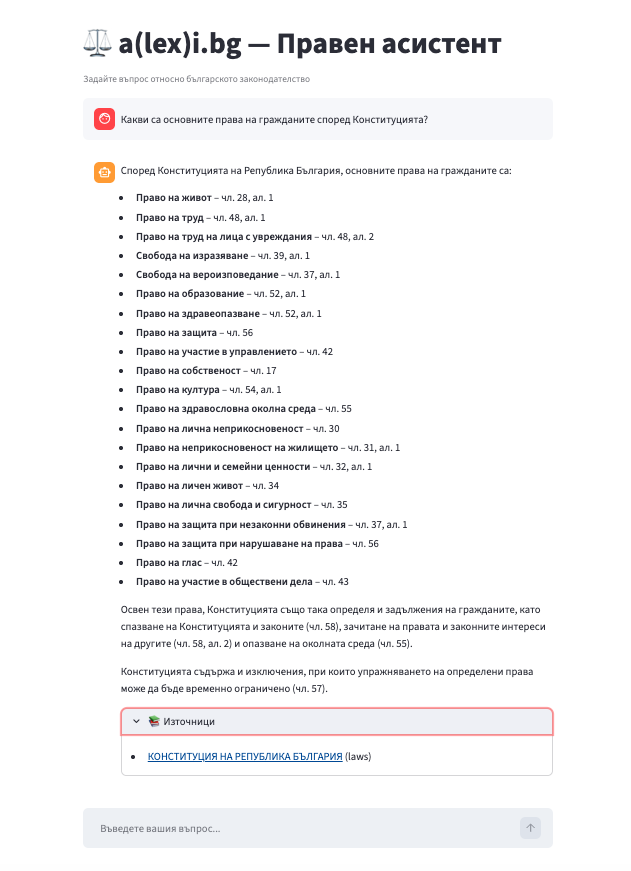
Bulgarian legislation is publicly available on lex.bg, but finding the right article in the right law for a specific question is tedious. You either know exactly where to look, or you spend a long time scrolling through dense legal text. I wanted to build something that could answer natural-language questions about Bulgarian law by pointing to the actual source — not hallucinating an answer, but grounding it in real legal text.
The result is a(lex)i.bg (a wordplay on “AI” and “lex.bg”): a fully local RAG system that crawls laws, news articles, and forum discussions from lex.bg, processes them through an ETL pipeline, and serves answers through a chat interface. Everything runs locally — no API keys to OpenAI or any external LLM provider. Just MongoDB, Qdrant, Ollama, and a few well-chosen models.
Architecture
The system has two main pipelines and a serving layer:
System Overview
graph TB
subgraph Presentation
UI[Streamlit Chat UI]
API[FastAPI REST API]
CLI[CLI Entry Points]
end
subgraph RAG Pipeline
QE[Query Expander<br/>Ollama / BgGPT]
VR[Vector Retriever<br/>BGE-M3]
RR[Reranker<br/>mMiniLM multilingual]
AG[Answer Generator<br/>Ollama / BgGPT]
end
subgraph ETL Pipeline
CR[Crawlers<br/>Legal · News · Forum]
CL[Cleaner]
CH[Chunker<br/>Legal-aware splitting]
EM[Embedder<br/>BGE-M3]
end
subgraph Infrastructure
MDB[(MongoDB)]
QD[(Qdrant)]
OL[Ollama]
end
UI --> API
API --> QE
CLI --> CR
CLI --> CL
CLI --> CH
CLI --> EM
QE --> OL
QE --> VR
VR --> QD
VR --> RR
RR --> AG
AG --> OL
CR -->|raw docs| MDB
CL -->|cleaned docs| MDB
CH -->|chunks| MDB
EM -->|embeddings| QD
Data Pipeline
flowchart LR
A[lex.bg] -->|Crawl| B[Raw Documents<br/>MongoDB]
B -->|Clean| C[Cleaned Documents<br/>MongoDB]
C -->|Chunk| D[Chunks<br/>MongoDB]
D -->|Embed| E[Embedded Chunks<br/>Qdrant]
Query Flow
flowchart LR
Q[User Query] --> QE[Query Expander]
QE --> VR[Vector Retriever]
VR --> QD[(Qdrant)]
QD --> RR[Reranker]
RR --> AG[Answer Generator]
AG --> OL[Ollama / BgGPT]
OL --> R[Answer + Sources]
The ETL pipeline takes raw HTML from lex.bg and turns it into searchable vector embeddings. The RAG pipeline takes a user question, expands it, retrieves relevant chunks, reranks them, and generates an answer grounded in the retrieved context. The serving layer exposes this through a FastAPI API and a Streamlit chat UI.
The ETL Pipeline
Crawling
lex.bg hosts several types of content, so I built three specialized crawlers:
-
LegalDocCrawler— crawls the main legal document tree (laws, codes, the constitution, ordinances, regulations). It usesrequests+BeautifulSoupto fetch tree pages, discover document links, and extract the legal text. Each document category has its own URL on lex.bg (e.g.,lex.bg/laws/tree/lawsfor laws,lex.bg/laws/tree/codefor codes). The crawler strips navigation, ads, and sidebars before extracting the body text, and it pulls metadata like publication dates when available. -
NewsCrawler— crawlsnews.lex.bgfor legal news articles. Samerequests+BeautifulSoupapproach. It extracts the title, author, publication date, and article body, filtering out non-article links with URL heuristics. -
ForumCrawler— crawlslex.bg/forumfor discussion threads. This one uses Selenium with a headless Chrome driver because the forum relies on JavaScript rendering. It scrolls the page to discover thread links, then navigates to each thread and extracts post content.
All three crawlers extend a BaseCrawler class that provides duplicate checking (skip if a document with the same link already exists in MongoDB), configurable request delays to be polite to the server, and a shared requests.Session with Bulgarian-friendly headers. The Selenium-based ForumCrawler extends BaseSeleniumCrawler, which adds headless Chrome setup via webdriver-manager.
Each crawled document is stored in MongoDB as a domain model — LegalDocument, NewsArticle, or ForumPost — with fields for the link, title, content, and category.
Cleaning
The cleaner reads all raw documents from MongoDB and produces CleanedDocument records. The cleaning is straightforward but necessary:
- Strip residual HTML tags that survived BeautifulSoup extraction
- Remove HTML entities (
&,{, etc.) - Normalize whitespace — collapse horizontal runs, limit consecutive newlines to two
The cleaner processes all three document types (LegalDocument, NewsArticle, ForumPost) and skips documents that have already been cleaned, making it safe to re-run.
Chunking
This is where things get interesting for legal text. Generic text splitters chop documents at arbitrary character boundaries, which can split a legal article mid-sentence or separate a paragraph from its article number. Bulgarian legal documents have a specific structure:
- Глава (Chapter)
- Раздел (Section)
- Дял (Part)
- Чл. (Article — the most common unit)
- Ал. (Paragraph)
- Numbered points like
(1),(2)
I use langchain-text-splitters’s RecursiveCharacterTextSplitter with a custom separator list that respects this hierarchy:
_LEGAL_SEPARATORS = [
"\nГлава ", # Chapter boundaries
"\nРаздел ", # Section boundaries
"\nДял ", # Part boundaries
"\nЧл. ", # Article boundaries (most common split point)
"\nЧл.",
"\nАл. ", # Paragraph boundaries
"\n(", # Numbered paragraphs like (1), (2)
"\n\n", # Generic fallbacks
"\n",
". ",
", ",
" ",
"",
]
The splitter tries each separator in order, only falling back to the next when the current one doesn’t produce chunks small enough. This means most chunks split cleanly at article boundaries, which is exactly what you want for legal text retrieval. Chunks are sized at 1000 characters with 100-character overlap — large enough to keep full legal articles intact.
Each chunk is also prefixed with the document title (e.g., [Закон за задълженията и договорите] Чл. 45...). This is a simple trick that significantly improves embedding quality — the model knows which law a chunk belongs to, even when the chunk text alone doesn’t mention it.
Embedding
The embedder loads all chunks from MongoDB, computes vector embeddings using BAAI/bge-m3 — a multilingual model that produces 1024-dimensional vectors and understands Bulgarian legal terminology well. It processes chunks in batches of 64 for efficiency and skips chunks that already exist in Qdrant. The collection uses cosine similarity, and each point stores the full chunk content plus metadata (document category, platform, title) in the payload.
I initially started with the English-only all-MiniLM-L6-v2 (384-dim) but the retrieval quality for Bulgarian legal queries was poor — it would match on surface-level word overlap rather than semantic meaning. Switching to BGE-M3 was a significant upgrade.
The RAG Pipeline
When a user asks a question, the RAG pipeline runs four stages:
Query Expansion
A single query often misses relevant documents because the user’s phrasing doesn’t match the legal text’s vocabulary. The query expander sends the original question to Ollama (running BgGPT) and asks it to generate alternative formulations that preserve the original meaning but use different wording.
For example, “Какви са правата на наемателя?” (What are the tenant’s rights?) might expand to:
- The original query
- “Какви права има наемателят по закон?” (What rights does a tenant have by law?)
- “Задължения на наемодателя към наемателя” (Obligations of the landlord to the tenant)
This improves recall — different phrasings match different chunks in the vector space.
Vector Retrieval
Each expanded query is embedded using the same BGE-M3 model used during indexing, then searched against Qdrant. The retriever fetches top_k * 3 candidates per query (to give the reranker a larger pool) and deduplicates across all expanded queries by chunk ID.
Cross-Encoder Reranking
Vector similarity is a rough proxy for relevance. A bi-encoder (BGE-M3) encodes query and document independently, so it can miss nuanced relevance signals. The cross-encoder (cross-encoder/mmarco-mMiniLMv2-L12-H384-v1 — a multilingual variant) scores each (query, chunk) pair jointly, which is more accurate but slower — that’s why we only run it on the top candidates from the retriever, not the entire collection. Using a multilingual reranker instead of the English-only ms-marco-MiniLM-L-4-v2 was critical — the English model couldn’t properly distinguish relevant Bulgarian legal text from tangentially related documents.
The reranker also applies two filters:
- A minimum score threshold to drop clearly irrelevant chunks
- A gap filter — if the top-scoring chunk is much more relevant than the rest, only chunks within 2 points of the best score are kept
This prevents the generator from being distracted by marginally relevant context.
Answer Generation
The reranked chunks are formatted into a context block and sent to Ollama along with the user’s question. The system prompt instructs the model to:
- Answer in Bulgarian
- Cite specific articles, paragraphs, and points from the relevant laws
- Explicitly state when information is incomplete or uncertain
- Base answers solely on the provided context
The response includes the generated answer plus a list of source references (title, link, document category) so the user can verify the answer against the original legal text.
Tech Stack and Design Decisions
Clean Architecture
The project follows a clean architecture layout:
alexi_bg/
├── domain/ — Pure data models, no I/O
├── application/ — Business logic (crawlers, preprocessing, RAG)
├── infrastructure/ — External services (MongoDB, Qdrant, Ollama, FastAPI)
└── ui/ — Streamlit frontend
The domain layer defines Pydantic models (LegalDocument, Chunk, EmbeddedChunk, RAGResponse) with no dependencies on infrastructure. The application layer contains the crawlers, ETL stages, and RAG pipeline components. The infrastructure layer wraps MongoDB, Qdrant, and Ollama behind lazy-connecting clients. This separation makes it easy to swap out any external service without touching the business logic.
MongoDB + Qdrant Dual-Store
MongoDB stores the raw documents, cleaned documents, and chunks — all the structured data that needs querying by fields like document_id, link, or document_category. Qdrant stores the vector embeddings for similarity search. This dual-store approach plays to each database’s strengths: MongoDB for flexible document storage and field-based queries, Qdrant for fast approximate nearest neighbor search.
Both clients use lazy initialization — the MongoConnector and QdrantConnector classes create the actual connection on first use, not at import time. This means you can import the modules without having the databases running, which is useful for testing and CLI help text.
BGE-M3 for Embeddings
I chose BAAI/bge-m3 over API-based embedding services (OpenAI, Cohere) because it runs locally (no API costs, no data leaving the machine) and it’s a multilingual model that handles Bulgarian text well. It produces 1024-dimensional embeddings with cosine similarity.
For a production system with millions of documents, you’d want GPU inference. For a few thousand Bulgarian legal documents, BGE-M3 on CPU is adequate (embedding is a one-time cost per crawl cycle).
BgGPT via Ollama for Local LLM Inference
Ollama makes it trivial to run open-weight models locally. The project uses it for two tasks: query expansion and answer generation. The OllamaClient is a thin wrapper around the /api/generate REST endpoint with configurable temperature, top-p, and max tokens.
I use BgGPT-Gemma-3-4B-IT from INSAIT Institute — a Bulgarian-adapted version of Google’s Gemma 3. It produces noticeably more natural Bulgarian text and better legal citations compared to generic multilingual models. The GGUF quantized version runs comfortably in Docker via Ollama. All prompts are in Bulgarian, and the system prompt explicitly instructs the model to cite legal sources.
Lessons Learned
Legal-aware chunking matters more than model size. My first attempt used a generic RecursiveCharacterTextSplitter with default separators. The retrieval quality was mediocre — chunks would start mid-article and end mid-sentence. Switching to Bulgarian legal structure separators (Чл., Ал., Глава) and prefixing chunks with the document title made a bigger difference than upgrading the embedding model.
Query expansion is cheap and effective. Adding 2-3 alternative phrasings of the user’s question costs one extra Ollama call (a few seconds) but noticeably improves recall. Legal text uses formal vocabulary that rarely matches how people naturally ask questions. The expanded queries bridge that gap.
Cross-encoder reranking is the biggest quality lever. The bi-encoder retriever casts a wide net, but many of the top-k results are only superficially similar. The cross-encoder reranker consistently pushes the truly relevant chunks to the top. The gap filter (dropping chunks more than 2 points below the best score) was a simple addition that eliminated most noise from the generated answers.
Multilingual models are non-negotiable for non-English RAG. My first iteration used English-only models for both embedding and reranking. The retrieval was terrible — asking about constitutional rights would return chunks from the Tax Code because both mention “права” (rights). Switching to BAAI/bge-m3 for embeddings and mmarco-mMiniLMv2 for reranking transformed the results. For the LLM, INSAIT’s BgGPT (a Bulgarian-adapted Gemma 3) produces far more natural and accurate Bulgarian text than generic multilingual models.
Lazy initialization saves headaches during development. Making the MongoDB and Qdrant clients connect on first use (not at import time) means the CLI can show help text, tests can import modules, and you can work on one part of the system without having all infrastructure running. It’s a small pattern that pays off constantly.
Wrapping Up
a(lex)i.bg is a focused project — it does one thing (answer questions about Bulgarian law) and tries to do it well. The architecture is intentionally simple: crawl, clean, chunk, embed, retrieve, rerank, generate. No agent frameworks, no complex orchestration, no cloud dependencies. Just a clean pipeline that runs on a laptop.
Credits
The project architecture — DDD layers, crawler patterns, MongoDB + Qdrant dual-store, preprocessing pipeline, and RAG retrieval flow — was heavily inspired by the LLM Engineer’s Handbook by Paul Iusztin and Maxime Labonne. Their companion repository is an excellent reference for building production-grade LLM systems. I simplified their setup by removing ZenML pipelines and AWS/SageMaker dependencies, and adapted it for a local-first, Bulgarian-focused use case.
The full source code is available on GitHub.